Guía de usuario
Una guía completa para trabajar con tus datos en ISLdata.
ISLdata es un sistema de gestión de datos diseñado para investigación de campo. Conecta la recolección de datos (vía ODK o importación manual), la organización de datos y la generación de reportes en un solo espacio de trabajo. Esta guía cubre todo lo que necesitas saber como usuario cotidiano del sistema.
Al iniciar sesión, llegarás al Data Viewer — la interfaz principal donde interactúas con todos tus datos. El Data Viewer se organiza en torno a cuatro conceptos centrales:
| Concepto | De qué se trata |
|---|---|
| Fuentes | Colecciones de datos crudos — sincronizadas automáticamente desde ODK Central o ESRI Survey123, importadas desde hojas de cálculo o ingresadas manualmente. Cada fuente es una tabla de registros con campos definidos. |
| Vistas | Ventanas personalizadas a tus datos. Una vista puede provenir de una sola fuente o unir varias fuentes, mostrando solo los campos que elijas en el orden que quieras. |
| Paneles | Resúmenes visuales que combinan gráficos y widgets de datos en una sola página. Útiles para monitorear el avance de la recolección de datos o métricas clave. |
| Reportes | Documentos estructurados que combinan texto narrativo, gráficos embebidos y tablas de datos — exportables como PDF o HTML. |
Todos tus datos viven dentro de un espacio de trabajo — un entorno aislado con sus propias fuentes, vistas, usuarios y registro de auditoría. Si necesitas acceder a un espacio de trabajo distinto, contacta a tu administrador.
Dónde aterrizas
Por defecto, al iniciar sesión llegas a la lista de Fuentes de tu espacio de trabajo. Si un administrador ha configurado una página de inicio del espacio, aterrizarás en ese panel — útil para equipos que quieren que un tablero de estado del proyecto, un resumen de conteo de muestras o un mapa de envíos recientes sea lo primero que todos vean. La navegación de la barra lateral es la misma en cualquier caso, por lo que siempre puedes saltar a Fuentes, Vistas, Paneles o Reportes desde ahí.
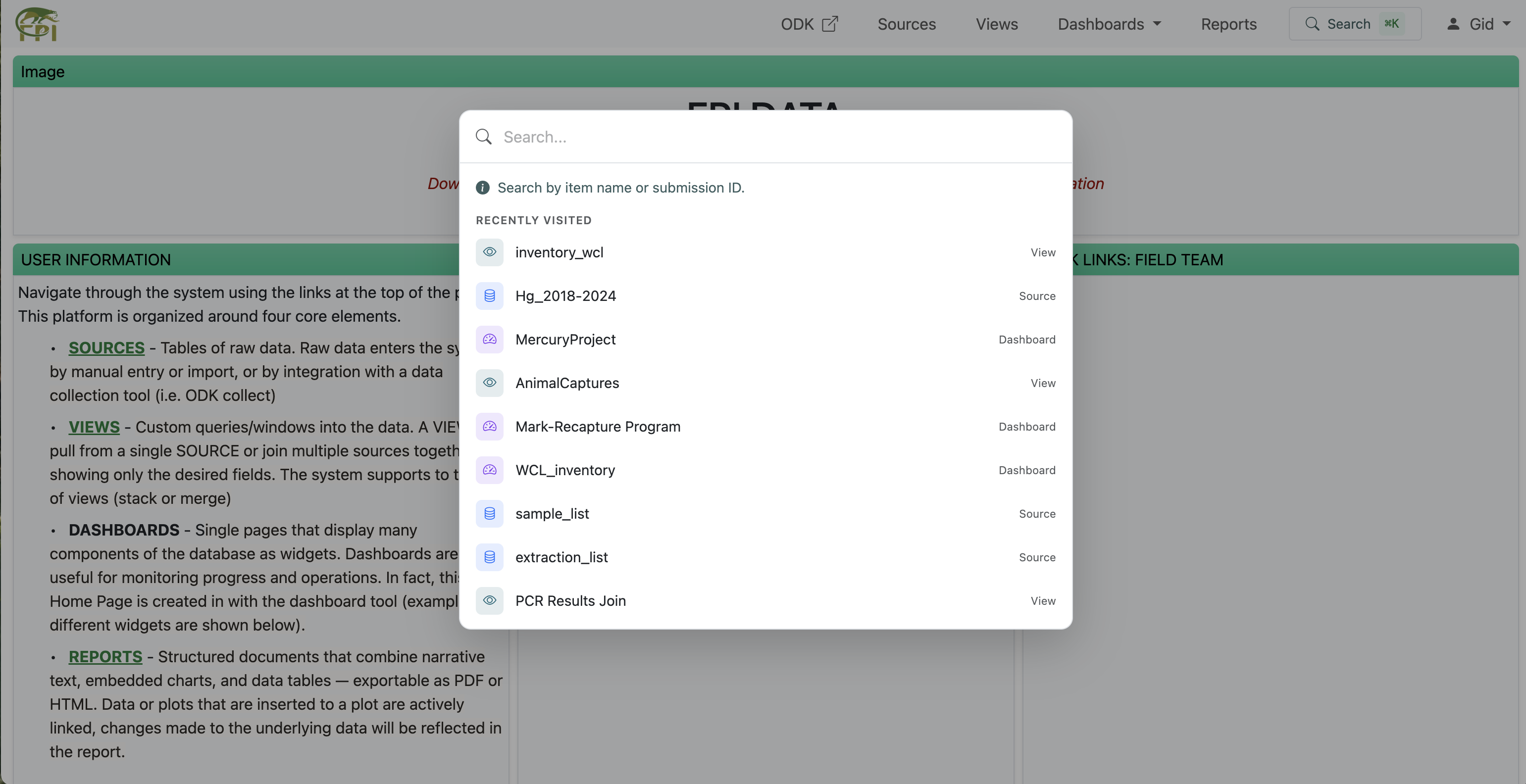
Encontrar cosas rápido
La cabecera incluye una barra de búsqueda global que admite dos formas de buscar:
- Por nombre de elemento — escribe cualquier parte del nombre de una fuente, vista, panel o reporte al que tengas acceso. Las coincidencias aparecen agrupadas por tipo.
- Por ID de envío — pega el ID único de un envío individual (el identificador que se muestra en las páginas de envíos individuales y se usa en los enlaces de los registros). La barra de búsqueda reconoce el formato del ID y te lleva directamente a ese envío.
Debajo del cuadro de búsqueda hay una lista de Visitados recientemente — los elementos que abriste hace poco, cada uno etiquetado con su tipo (Fuente, Vista, Panel, etc.). Juntos cubren ambas formas de búsqueda: saltar a una sección del espacio de trabajo cuando recuerdas su nombre, y volver a aquello en lo que estabas trabajando.
Entender las Fuentes
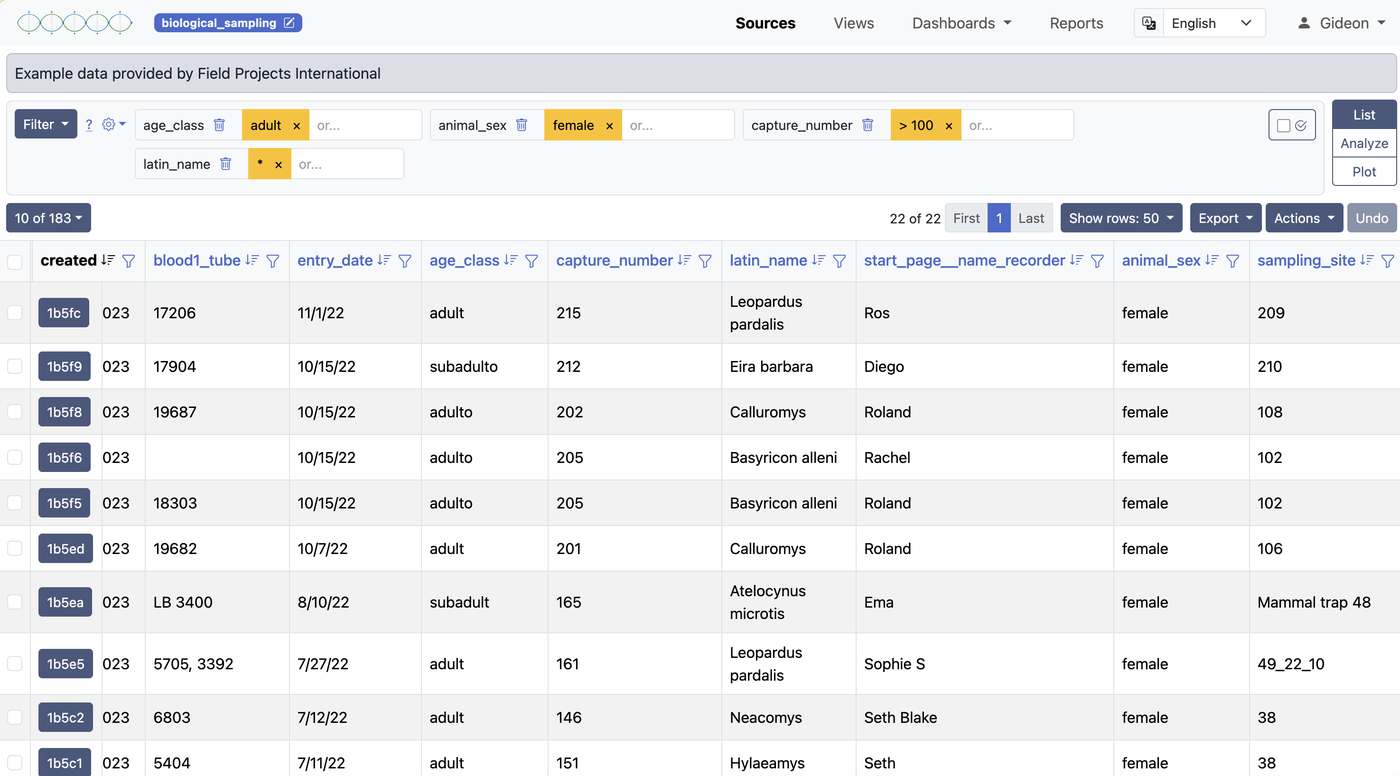
Una fuente es una colección de registros — tus datos crudos. Piénsala como una hoja de cálculo o una tabla de base de datos. Cada fuente tiene un conjunto de campos definidos (columnas), y cada registro (fila) contiene datos para esos campos.
Las fuentes entran al sistema de tres formas:
- Sincronización automática desde un servicio de recolección de datos. Si tu organización usa ODK Central o ESRI Survey123, ISLdata se conecta directamente con esas plataformas. Los envíos se importan automáticamente — normalmente a los pocos minutos de subirse desde un dispositivo móvil — y cada formulario corresponde a una fuente. La fuente y todos sus campos se crean por ti.
- Importación desde una hoja de cálculo. Creas una fuente en blanco e importas un archivo CSV o Excel. Los encabezados de columna en el archivo se convierten en las definiciones de campos de la fuente, estableciendo en un solo paso tanto los campos como su orden.
- Configuración manual campo por campo. Creas una fuente y defines cada campo individualmente, especificando el nombre, el tipo y otras opciones de cada uno. Esto es útil cuando construyes una colección estructurada desde cero en vez de a partir de un dataset existente.
Una vez que la fuente existe, también puedes ingresar registros uno a uno a través del formulario de entrada de datos — útil para registrar eventos individuales o resultados de laboratorio a medida que ocurren.
Las fuentes son la base de todo lo demás en el sistema. Las vistas, paneles y reportes hacen referencia a datos que se originan en las fuentes.
Las fuentes admiten alias de campo y orden de columnas, por lo que puedes darles a los campos nombres legibles y ordenarlos sin afectar las importaciones. Para una reorganización más amplia — seleccionar un subconjunto de campos, unir varias fuentes o configurar una presentación adaptada a un equipo específico — crea una vista.
Navegación y filtrado
Al seleccionar una fuente o vista desde la barra lateral, se abre en la tabla de datos. Los controles de navegación y filtrado funcionan igual estés mirando una fuente o una vista. Desde aquí puedes navegar registros, controlar qué columnas son visibles, ordenar por cualquier campo y aplicar filtros para acotar los datos.
Visibilidad de columnas
Las fuentes recolectadas mediante formularios ODK o importadas desde hojas de cálculo grandes suelen contener muchos campos. Puedes alternar la visibilidad de columnas para mostrar solo los campos relevantes para tu tarea actual. La configuración de visibilidad de cada usuario se guarda de forma independiente, así que tus preferencias de visualización no afectan a nadie más.
Los administradores también pueden definir un diseño de columnas por defecto que todos los usuarios verán al abrir por primera vez una fuente o vista — y al que cualquier usuario puede volver si quiere reiniciar su configuración.
Ordenamiento
Haz clic en cualquier encabezado de columna para ordenar los datos por ese campo. Haz clic de nuevo para invertir el orden. El ordenamiento se aplica encima de cualquier filtro activo.
Filtrado
El sistema de filtros va de lo simple a lo complejo según tu necesidad. En su forma más simple, eliges un campo y un valor para coincidir. Puedes apilar varios filtros — se combinan con lógica Y, así que los registros deben cumplir todas las condiciones para aparecer.
Para coincidencias más precisas, los filtros aceptan expresiones regulares, lo que permite búsquedas por patrones en campos de texto. Esto es útil para encontrar valores con un prefijo común, un formato específico o un rango de códigos.
Se pueden guardar filtros por defecto sobre una fuente o vista de modo que ciertas condiciones siempre estén activas al abrirla — por ejemplo, mostrando automáticamente solo los registros de la temporada de campo actual. Se configuran en la fuente o la vista, y los usuarios pueden agregar más filtros encima durante la sesión.
Crear una Fuente
Hay tres formas distintas de crear una fuente en ISLdata. Entender la diferencia te ayuda a elegir el enfoque adecuado.
1. Configuración manual campo por campo
Ve a Fuentes y haz clic en Nueva fuente. Tras nombrar la fuente, agregas cada campo uno a uno — especificando el nombre, el tipo y las opciones de cada uno. Esto te da el máximo control sobre la estructura y es una buena opción cuando diseñas una colección desde cero, como una tabla de referencia de especies o un formulario de registro de muestras.
2. Configuración por importación
Crea una fuente en blanco e importa inmediatamente una hoja de cálculo (CSV o XLSX). Los encabezados de columna de tu archivo se convierten en las definiciones de campos — nombres, orden y todo. Es la forma más rápida de llevar un dataset existente a ISLdata y que la estructura refleje automáticamente tu hoja de cálculo.
3. Creación automática desde un servicio de recolección de datos
Si tu espacio de trabajo está integrado con ODK Central o ESRI Survey123, las fuentes se crean automáticamente — sin acción requerida. Cuando llegan envíos desde el servidor, ISLdata crea la fuente si aún no existe, establece todos los campos a partir de la definición del formulario y carga los registros iniciales. Los nuevos envíos siguen sincronizándose continuamente.
Editar la configuración de la fuente
Cada fuente tiene una página de configuración donde puedes gestionar sus campos y opciones. Para acceder, abre la fuente y haz clic en el botón Editar (o el icono de engranaje).
Alias de campos (nombres para mostrar)
Los nombres de campos heredados de formularios ODK o archivos importados suelen ser técnicos o abreviados. Puedes asignar un alias — un nombre legible — a cualquier campo. El identificador original del campo se conserva internamente y sigue usándose para mapear datos, por lo que renombrar nunca rompe importaciones ni integraciones. Es un cambio puramente visual.
Tipos de campo
Cada campo tiene un tipo que determina cómo se almacenan, ordenan y usan sus datos en cálculos. Los tipos disponibles son:
| Tipo | Descripción |
|---|---|
| Texto | Texto libre. Tipo por defecto para datos importados. |
| Entero | Valores numéricos enteros. Permite ordenamiento numérico y funciones de agregación como suma y promedio. |
| Decimal (Float) | Valores numéricos con decimales. Útil para mediciones, coordenadas o cualquier dato que requiera precisión decimal. |
| Adjunto | Un campo que contiene la referencia a un archivo binario (imagen, documento, etc.) asociado al registro. |
| Lookup | Un campo que enlaza con un registro de otra fuente. Cuando el usuario hace clic en un valor de lookup en la tabla, se abre una ventana emergente con el registro completo de la fuente conectada — sin salir de la página actual. Esto facilita las referencias cruzadas entre datos relacionados. |
| Secuencia | Un campo numérico auto-incremental. Útil para generar identificadores secuenciales únicos dentro de una fuente. |
Puedes cambiar el tipo de un campo en cualquier momento, pero ten en cuenta que los datos existentes se validarán contra el nuevo tipo. Por ejemplo, convertir un campo de texto a entero marcará los valores no numéricos.
Opciones de campo
Además del tipo, cada campo admite opciones adicionales:
- Requerido — marca un campo como requerido para que los registros no se puedan guardar sin un valor en ese campo. Útil para asegurar la calidad en identificadores clave.
- Incluir en la vista por defecto — designa un campo como parte del diseño de columnas por defecto. Los campos no incluidos quedan ocultos por defecto pero siguen accesibles desde los controles de visibilidad.
Orden de campos
Puedes reordenar los campos en la configuración de la fuente. El nuevo orden se convierte en la secuencia por defecto de columnas en la tabla de datos y se preserva en futuras importaciones — los datos entrantes se mapean por nombre de campo, no por posición, así que reordenar nunca causa errores de mapeo.
Etiquetas en otros idiomas
Si tu equipo trabaja en varios idiomas, puedes añadir etiquetas alternativas a los nombres de campo. Esto permite a los usuarios ver los encabezados de los campos en su idioma preferido sin cambiar la estructura subyacente de los datos.
Importar datos
El asistente de importación te guía para traer datos externos a una fuente. Es una de las operaciones más comunes en ISLdata y admite archivos CSV y Excel (XLSX).
Paso 1 — Sube tu archivo
Selecciona el archivo desde tu computadora. ISLdata lo analizará y te mostrará una vista previa con las columnas y las primeras filas para que verifiques que se leyó correctamente.
Paso 2 — Mapeo de campos
Si la fuente ya tiene campos definidos (de una importación previa o de ODK), mapearás las columnas de tu archivo a los campos existentes. Si es una fuente nueva, las columnas de tu archivo crearán la estructura de campos. Puedes omitir columnas que no quieras importar.
Paso 3 — Revisión en staging
Antes de confirmar los datos, estos llegan a un área de staging. Puedes revisar los registros en staging, hacer revisiones puntuales y detectar problemas antes de que entren a la fuente. Esta es tu red de seguridad — nada es definitivo hasta que confirmas.
Paso 4 — Confirmar
Cuando estés conforme con los datos en staging, confirma la importación. Los registros pasan a formar parte de la fuente y se registra un evento de auditoría con quién importó qué y cuándo.
Las importaciones grandes pueden tardar en procesarse. No abandones la página hasta que se confirme la operación. Si algo sale mal durante la importación, los datos en staging permanecen disponibles — no se pierde nada.
Edición en línea
Puedes editar valores de campos directamente en la tabla de datos haciendo clic en una celda. Es útil para corregir errores de captura, actualizar campos de estado o rellenar valores faltantes sin salir de la vista de tabla.
Editar varios registros a la vez
ISLdata no tiene un botón ni modo separado de "edición en lote" — en su lugar, la edición de varios registros funciona por selección de registros. Selecciona varios registros con las casillas en cada fila. Una vez seleccionados dos o más, cualquier edición que hagas a un campo en uno de esos registros se aplica automáticamente a todos los seleccionados.
Es decir, el flujo es: selecciona los registros que quieres actualizar, edita el valor del campo en cualquiera de ellos, y el cambio se propaga a todos. Puedes usar filtros primero para acotar los registros visibles y luego seleccionarlos todos a la vez para apuntar exactamente al conjunto correcto.
La edición de varios registros no aplica a campos de adjunto — sería inusual asignar el mismo archivo a muchos registros a la vez, por lo que este comportamiento se excluye a propósito.
Cada edición se registra en la auditoría con el usuario, marca de tiempo y los valores antiguo y nuevo — ya sea que hayas editado un registro o cincuenta a la vez. Esto crea un historial completo de cambios revisable por administradores.
Adjuntos
Los registros pueden tener archivos binarios adjuntos — fotografías, documentos escaneados, PDFs o cualquier otro tipo de archivo. Los adjuntos de envíos de formularios ODK (como fotos tomadas en campo) se sincronizan automáticamente. También puedes subir adjuntos manualmente desde la vista detallada del registro.
Visor integrado
Los tipos de archivo comunes se abren directamente en un visor emergente sin necesidad de descargar el archivo. Las imágenes admiten controles de zoom y rotación, y cualquier cambio de rotación que hagas en el visor se guarda — así que si una foto de campo se capturó de lado, puedes corregirla una vez y queda corregida. Los PDFs se abren en un lector integrado donde puedes desplazarte por las páginas y usar búsqueda de texto para encontrar contenido dentro del documento.
Los archivos que no se pueden previsualizar en el navegador igualmente pueden descargarse directamente a tu dispositivo.
Copiar-A
Copiar-A es el mecanismo principal para mover registros a lo largo de un pipeline de investigación. La idea central es mantener una fuente separada para cada etapa de un proceso — recolección de muestras, procesamiento en laboratorio, resultados, etc. — y usar Copiar-A para hacer avanzar los registros de una etapa a la siguiente. Cada operación de copia registra el avance y crea un enlace trazable entre etapas.
Cómo funciona
Selecciona uno o más registros en una fuente (o vista), activa Copiar-A y elige la fuente destino. Los registros se copian, y opcionalmente puedes sobreescribir valores específicos como parte de la copia — por ejemplo, fijar una "Fecha de recepción" o un campo "Estado" en la fuente destino a un valor fijo en el momento del traslado.
El campo origin_id
Cada fuente tiene un campo de sistema llamado origin_id. Cuando los registros llegan vía Copiar-A, este campo se llena automáticamente con el ID del registro originario en la fuente de origen. El origin_id funciona como un lookup — puedes hacer clic en él para abrir el registro de origen en una ventana emergente. Esto te da un enlace hacia atrás: desde cualquier etapa, puedes rastrear un registro hasta su origen.
Enlaces hacia adelante (auto-incremento + lookup)
También puedes configurar un enlace hacia adelante — de modo que cuando copias un registro a una fuente destino, el registro de origen se actualice automáticamente con el ID del nuevo registro recién creado. Esto requiere dos pasos en la configuración:
- Crea un campo auto-incremental en la fuente destino (para generar un ID único para cada nuevo registro).
- Crea un campo lookup en la fuente de origen que apunte a ese campo auto-incremental en la destino.
Una vez configurado, el panel de Copiar-A mostrará una opción etiquetada "Vincular nuevo(s) registro(s) de vuelta a [nombre de la fuente]:". Está activado por defecto cuando se detecta un lookup compatible. Puedes desactivarlo si necesitas copiar sin crear el enlace de regreso para un lote en particular.
Sin la configuración del enlace hacia adelante, el rastreo del pipeline es solo hacia atrás — siempre puedes rastrear de dónde vino algo, pero no ver automáticamente a dónde fue. Con la combinación de auto-incremento y lookup, obtienes trazabilidad bidireccional en todo tu flujo de trabajo.
Operaciones sobre registros
Duplicar registros
Los registros individuales se pueden duplicar dentro de la misma fuente. El duplicado se crea como un registro nuevo con su propio ID, así que puedes modificarlo de forma independiente. También puedes sobrescribir valores específicos durante la duplicación.
Archivar registros
Los registros se pueden archivar en lugar de eliminarse permanentemente. Los registros archivados se mueven a una colección separada y se ocultan de la vista por defecto, pero se pueden consultar y restaurar desde la vista de archivo. Este es el enfoque recomendado para eliminar registros que ya no necesitas — preserva los datos y el registro de auditoría.
Entender las Vistas
Una vista es una ventana virtual a tus datos. A diferencia de una fuente, una vista no almacena datos en sí — hace referencia a datos de una o más fuentes y los presenta según tu configuración. Si los datos de la fuente subyacente cambian, la vista refleja esos cambios automáticamente.
Las vistas tienen tres capacidades distintas. Primero, te permiten personalizar cómo ves los datos de una sola fuente — eligiendo qué campos mostrar, renombrándolos, reordenándolos y estableciendo filtros por defecto. Segundo, te permiten combinar datos de varias fuentes de dos formas distintas (apilando o uniendo — descritas a continuación). Tercero, y quizá lo más distintivo, puedes agregar campos completamente nuevos que existen solo en la vista — no presentes en ninguna fuente — para anotar, categorizar o derivar información dentro del contexto de esa vista.
Las vistas son no destructivas en su configuración: crear, renombrar, reordenar campos, agregar filtros o cambiar la configuración de una vista no tiene efecto sobre los datos de la fuente subyacente. Editar registros desde una vista es un comportamiento separado y opcional — consulta Edición desde una vista para más detalles.
Crear una vista de fuente única
Una vista de fuente única toma datos de una sola fuente y te permite personalizar la presentación. Para crearla, ve a Vistas y haz clic en Nueva vista, y luego selecciona tu fuente.
En el constructor de vistas puedes:
- Seleccionar campos — elige qué campos de la fuente aparecen en la vista. Deja fuera los metadatos o campos internos que no necesites.
- Renombrar campos — dales a los campos nombres más significativos en esta vista sin cambiar la fuente. Por ejemplo, renombrar
p_dobaFecha de nacimiento. - Reordenar campos — organiza las columnas en una secuencia lógica para tu flujo de trabajo.
- Establecer filtros por defecto — pre-configura filtros para que la vista siempre se abra mostrando un subconjunto específico de datos (por ejemplo, solo registros del año en curso).
- Establecer columnas visibles por defecto — controla qué campos son visibles por defecto al abrir la vista.
Campos propios de la vista
Esta es una de las capacidades más distintivas de ISLdata: puedes agregar campos a una vista que no tienen equivalente en ninguna de las fuentes subyacentes. Estos campos existen exclusivamente dentro de la vista, y cualquier dato ingresado en ellos se almacena ahí — no en la fuente.
Esto es realmente útil cuando quieres trabajar con un subconjunto específico de tus datos y construir una capa de interpretación o clasificación encima. Por ejemplo, podrías crear una vista de muestras de campo y agregar un campo solo-de-vista para un esquema de categorización relevante para el análisis de un equipo, sin que esa categorización ensucie la fuente original para los demás. La vista se vuelve tanto ventana como superficie de trabajo.
Los campos solo-de-vista se distinguen visualmente en la tabla — resaltados para que sea inmediatamente claro que no provienen de los datos subyacentes, eliminando ambigüedad sobre el origen de los valores.
Si decides que la información en un campo solo-de-vista debería formar parte de una fuente — por ejemplo, una vez que una categorización quede finalizada — usa la función Copiar-A para mover esos registros y sus valores a una fuente dedicada. Esto "gradúa" los datos desde un borrador analítico a una colección permanente y estructurada.
Combinar varias fuentes
Cuando tus datos viven en más de una fuente, ISLdata ofrece dos formas fundamentalmente distintas de reunirlos en una sola vista. Es importante entender cuál usar — sirven a propósitos analíticos diferentes y producen resultados distintos.
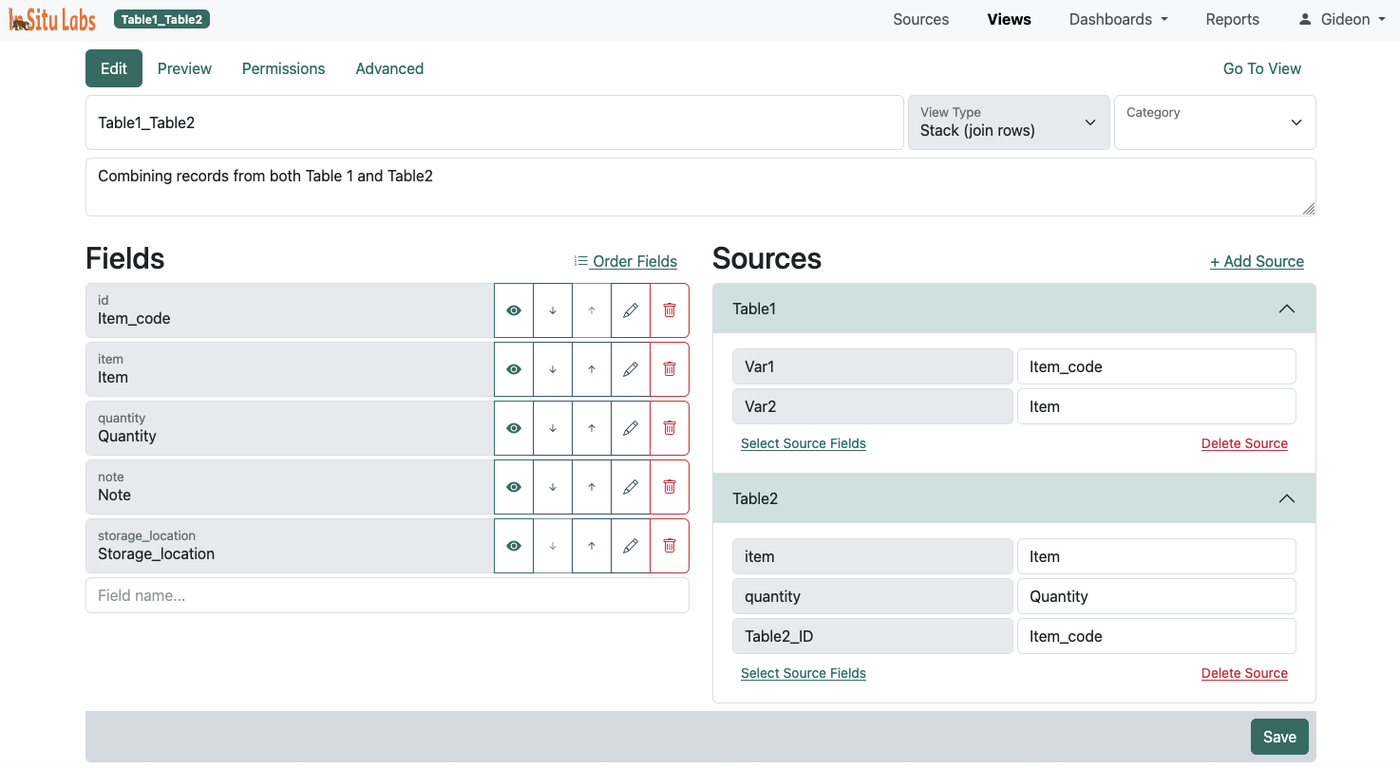
Vistas apiladas (Stack)
Una vista apilada coloca los registros de varias fuentes uno encima de otro en un dataset unificado. Los registros no se fusionan — permanecen como filas distintas. El número total de filas en una vista apilada es igual al total de registros combinados en todas las fuentes incluidas.
Para que esto funcione, mapeas los campos de cada fuente a los campos correspondientes de la vista. Por ejemplo, si una fuente llama a un campo collection_date y otra al mismo concepto sample_date, mapeas ambos a un único campo de la vista llamado "Fecha". ISLdata se encarga de la armonización para que los datos se alineen correctamente en la tabla.
Las vistas apiladas son ideales cuando quieres co-analizar datasets estructuralmente similares pero separados por año, geografía, fase del proyecto o institución — situaciones donde quieres una imagen combinada sin fusionar las identidades de los registros.
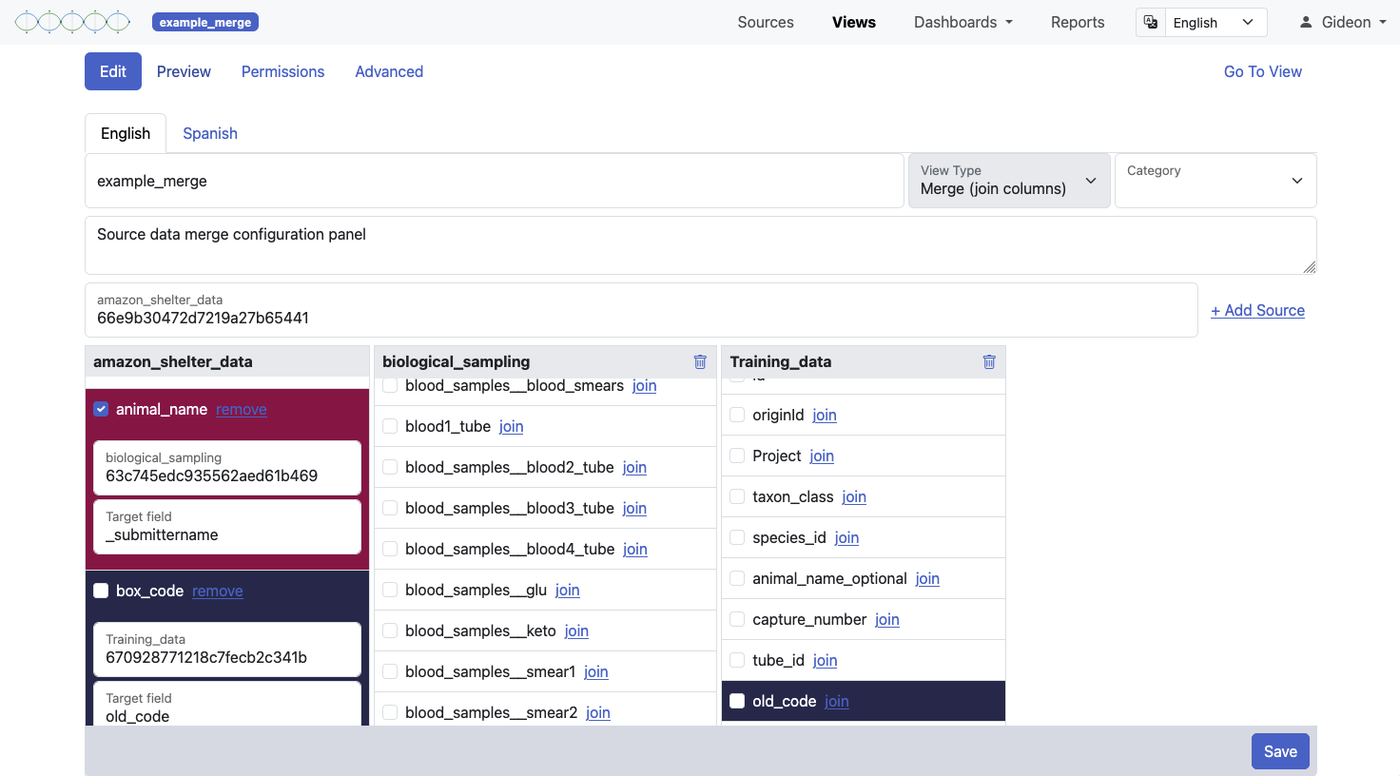
Vistas unidas (Merge)
Una vista unida funciona más como un JOIN tradicional de base de datos. Empiezas con una fuente principal y le agregas información de uno o más fuentes vinculadas — usando un campo identificador compartido (equivalente a una relación clave primaria / clave foránea) para emparejar registros entre fuentes.
El número de filas en una vista unida es igual al número de registros en tu fuente principal — ni más ni menos. Lo que cambia es el número de columnas: los campos de las fuentes vinculadas se agregan a cada registro donde coincide el campo clave. Para ayudarte a saber de dónde proviene cada campo, las columnas se codifican por color según su fuente en la vista.
Una vista unida es la opción correcta cuando quieres enriquecer un dataset central con información relacionada — por ejemplo, combinar una fuente de registro de muestras con una fuente de resultados, vinculadas por un ID de muestra compartido.
Para que las vistas unidas funcionen bien, los valores del campo clave deben coincidir exactamente entre fuentes. Asegura un formato consistente — "Site-01" y "Site 01" no coincidirán. Limpia tus datos de origen antes de crear vistas unidas si notas inconsistencias.
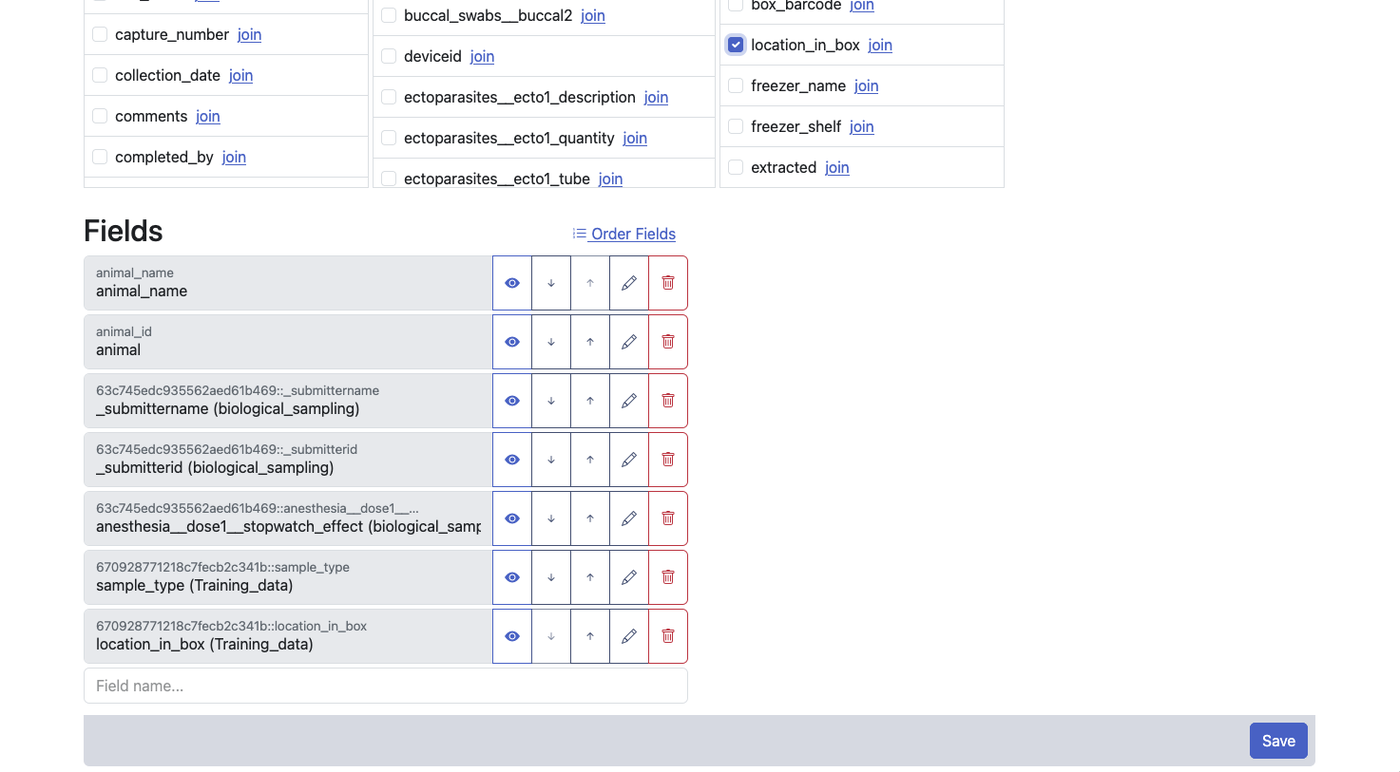
Una nota sobre integridad referencial
A diferencia de una base de datos relacional tradicional, ISLdata no impone integridad referencial entre fuentes vinculadas. Esto es intencional — la imposición estricta suele crear obstáculos en los flujos de datos de investigación, donde los datos llegan de forma incremental e imperfecta. Puedes lograr salvaguardas similares usando campos lookup para establecer relaciones entre fuentes y marcando campos críticos de enlace como requeridos. Esto te da la flexibilidad de un sistema basado en documentos con la disciplina organizativa del diseño relacional, aplicada donde más importa.
Edición desde una vista
Vale la pena diferenciar dos cosas distintas que podrías querer decir con "editar una vista", porque tienen consecuencias muy distintas.
Editar la configuración de la vista
Es lo que haces cuando abres la pantalla de edición de una vista — renombrar la vista, elegir qué campos son visibles, reordenarlos, cambiar filtros por defecto, ajustar cómo se combinan varias fuentes, etc. Nada de esto afecta los datos subyacentes de la fuente. Una vista es una presentación guardada; cambiar la presentación nunca altera los registros de los que se nutre. Puedes experimentar con la configuración de una vista con libertad.
Editar registros desde una vista
Este es un comportamiento separado y opcional. Cuando una vista tiene la edición de registros habilitada y tienes acceso de escritura, la tabla de datos dentro de esa vista se vuelve interactiva — hacer clic en una celda te permite cambiar su valor igual que en una fuente. El cambio se escribe en el registro original de la fuente y queda en el registro de auditoría; la vista es una ventana, no una copia, así que la fuente es el único lugar donde los datos realmente viven.
Esto funciona en vistas de fuente única y en vistas multi-fuente (apiladas y unidas). Si la edición no está habilitada en una vista, esta es de solo lectura y la tabla de datos actúa puramente como una ventana a la fuente — útil cuando quieres compartir una presentación curada de los datos sin dar a los usuarios la posibilidad de cambiar valores a través de ella.
Un patrón común es mantener el acceso de escritura directa a una fuente restringido a un grupo pequeño, mientras se expone al equipo más amplio una vista con edición habilitada. Las ediciones fluyen hacia la fuente a través de un conjunto curado de campos y filtros, y el registro de auditoría guarda quién cambió qué.
Vistas materializadas
Cuando una vista es compleja — combinando fuentes grandes, con múltiples uniones o haciendo agregaciones pesadas — consultarla en vivo en cada carga de página puede ser lento. Las vistas materializadas resuelven esto pre-computando y cacheando el resultado de la vista en segundo plano, para que los datos se carguen al instante al abrirla.
Las vistas materializadas están activadas por defecto para las vistas donde el sistema detecta que serían útiles. El caché se refresca automáticamente cuando el sistema detecta un cambio en la definición de la vista o en sus fuentes subyacentes, y también en una programación regular. Los administradores del espacio de trabajo también pueden disparar un refresco manual en cualquier momento si necesitan que la vista refleje cambios recientes de inmediato.
Si acabas de hacer un cambio importante en los datos y la vista aún no parece reflejarlo, es posible que el caché materializado se esté actualizando. Espera un momento o pídele a tu administrador que dispare un refresco manual.
Reducir y agrupar
La función Analyze está disponible en cualquier fuente o vista. Te permite resumir tus datos agrupando registros por uno o más campos y aplicando un cálculo en cada grupo — similar a una tabla dinámica en una hoja de cálculo, pero integrada directamente en el visor de datos.
Cómo usarla
Haz clic en el botón Analyze en cualquier fuente o vista. Se abrirá un panel donde:
- Selecciona una o más variables de agrupación — los campos cuyos valores distintos definen los grupos (por ejemplo Sitio, Especie, Mes).
- Elige la operación a realizar: conteo, suma, promedio, mínimo o máximo.
- Selecciona el campo al que se aplicará la operación.
El resultado es una tabla resumen mostrando una fila por grupo con el valor calculado. Puedes aplicar varias variables de agrupación para producir tablas cruzadas — por ejemplo, agrupando por sitio y por año para ver conteos desglosados en ambas dimensiones.
Las tablas resumen se pueden exportar directamente (ver Exportar datos) o agregar a un reporte para incluirse en un documento formateado.
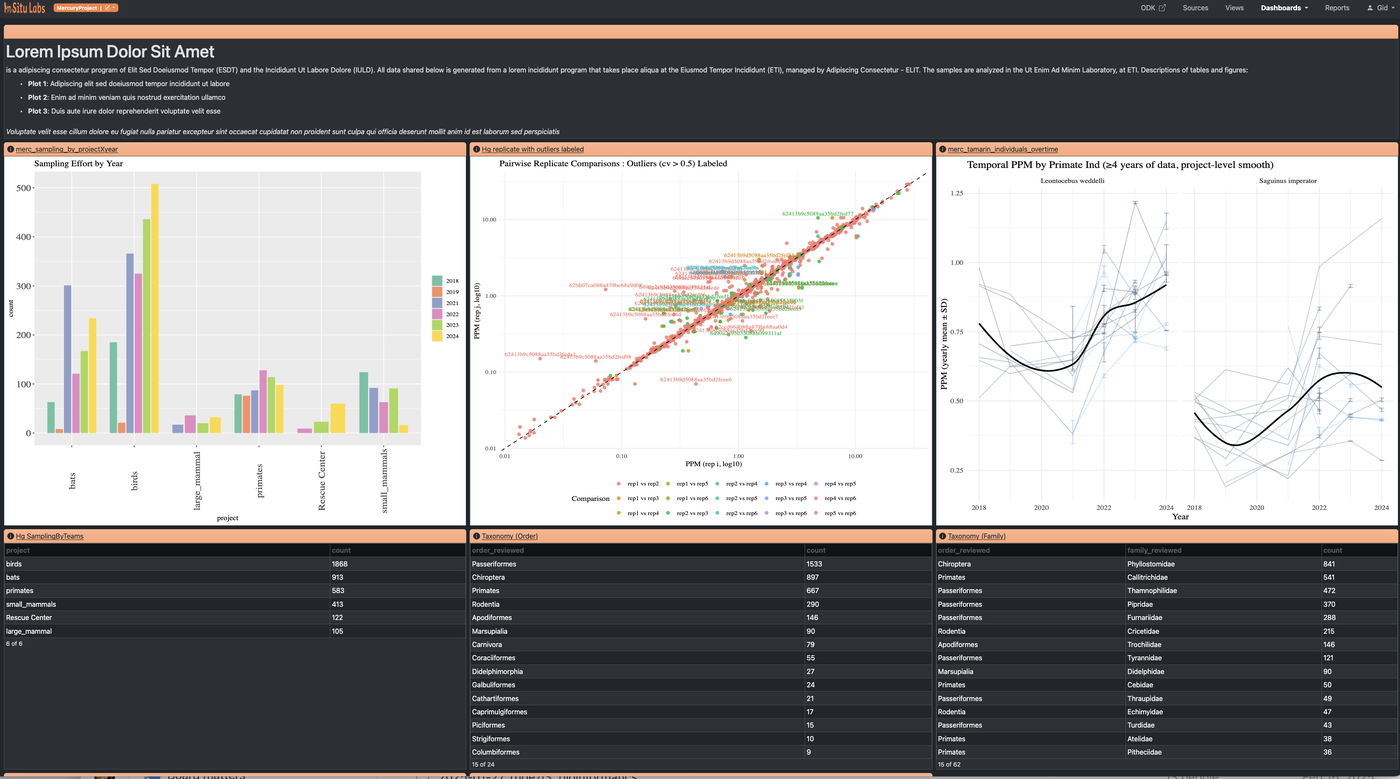
Paneles
Un panel es una página de widgets que reúne múltiples vistas de tus datos en un solo lugar. Los paneles son útiles para monitorear el avance de la recolección de datos, hacer seguimiento de métricas clave de un vistazo o compartir un resumen en vivo con colaboradores. Los widgets pueden mostrar:
- Gráficos y plots — visualizaciones guardadas de cualquier fuente o vista
- Resúmenes de datos — vistas agregadas o reducidas de tus datos
- Listas de registros — tablas en vivo de registros provenientes de una fuente o vista
- Bloques de texto enriquecido — encabezados, notas explicativas o contexto para otros lectores
Construir un panel
Ve a Paneles y crea uno nuevo. Desde el editor de paneles puedes agregar cualquiera de los tipos de widget anteriores, organizarlos en la página y configurar la fuente de datos y los filtros de cada widget de forma individual.
No tienes que construirlo todo desde el editor de paneles. Desde cualquier fuente o vista puedes enviar un gráfico o resumen directamente a un panel existente — o crear uno nuevo en el momento. Esto facilita ir construyendo un panel de forma incremental mientras trabajas con tus datos, sin tener que cambiar de contexto.
Reportes
Los reportes son documentos estructurados que mezclan escritura narrativa con contenido de datos en vivo. Están pensados para escribir hallazgos, producir resúmenes periódicos o compartir resultados con personas que necesitan más contexto del que ofrece un panel.
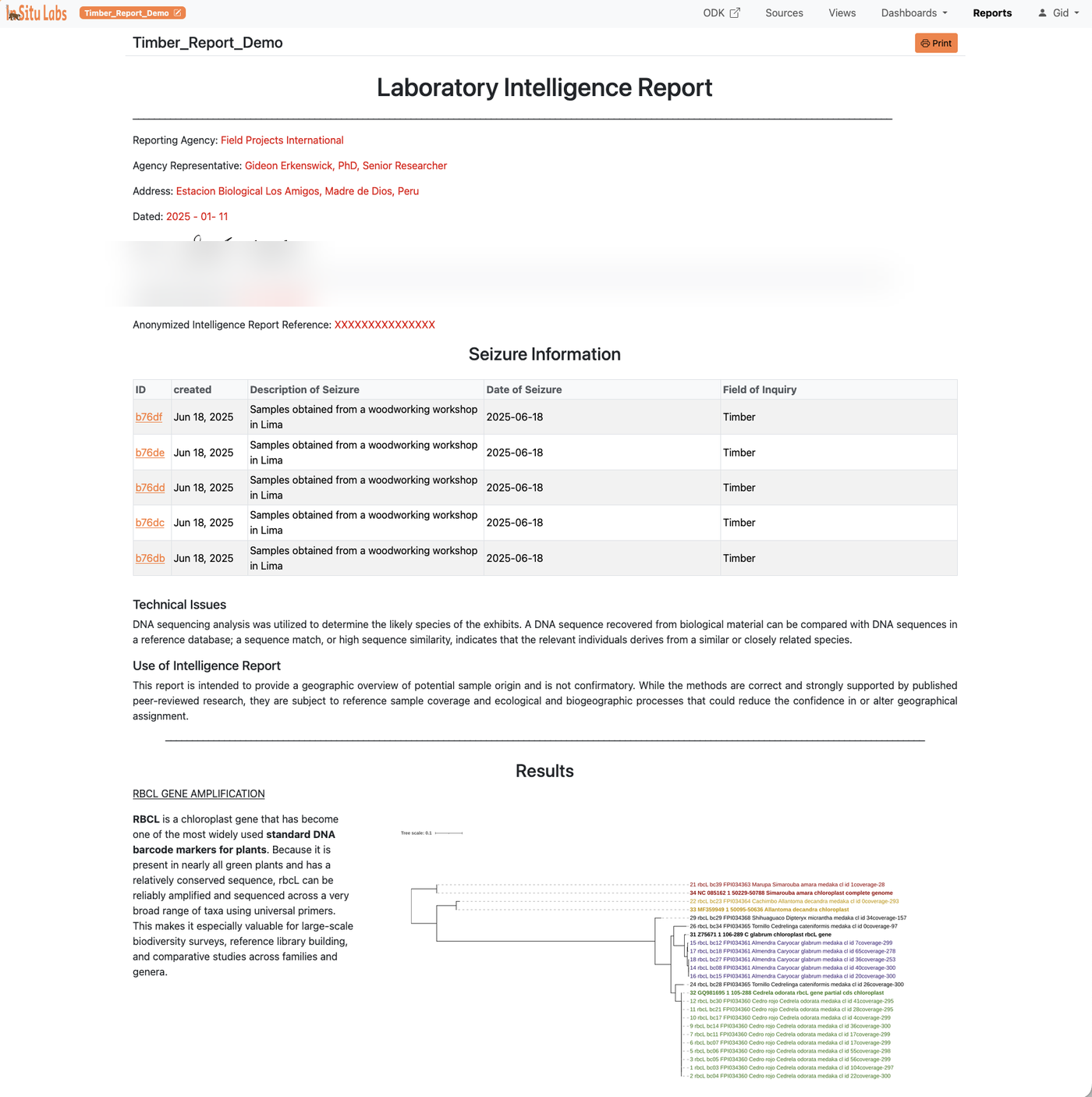
Qué puedes embeber
Un reporte puede contener cualquier combinación de lo siguiente, en cualquier orden:
- Gráficos guardados de cualquier fuente o vista
- Resúmenes y agregaciones de datos de cualquier fuente o vista
- Listas de registros provenientes de cualquier fuente o vista
- Imágenes externas — cargadas o enlazadas desde una URL
- Hipervínculos — a recursos externos o a otras partes del sistema
- Texto enriquecido — encabezados, párrafos de cuerpo, leyendas y narrativa formateada
Enlaces vivos a registros
Los registros listados dentro de un reporte son enlaces vivos. Hacer clic en un registro lo abre directamente en el sistema — siempre que tengas permiso para acceder a la fuente a la que pertenece. Esto hace que los reportes sean útiles no solo como resúmenes sino como herramientas de navegación, permitiendo a los lectores profundizar en cualquier registro individual que les llame la atención.
Exportar
Los reportes se pueden exportar como PDF (vía impresión) o compartir como HTML. El formato está diseñado para producir una salida limpia y profesional, adecuada para enviar a colaboradores, financiadores o socios institucionales que no tienen acceso al sistema.
Gráficos y visualizaciones
Los gráficos son los bloques de construcción de los paneles y reportes — diagramas, gráficos y cualquier otra representación visual de tus datos. Se crean usando código R, lo que te da toda la flexibilidad del ecosistema gráfico de R para cualquier visualización que necesites.
Crear un gráfico
Abre cualquier fuente o vista y selecciona la pestaña Plot. Esto abre un espacio de código donde escribes código R para generar tu visualización. Tus datos están disponibles automáticamente como un data.frame de R llamado data — sin necesidad de carga ni configuración.
Para renderizar tu gráfico, presiona Ctrl+Enter (Windows/Linux) o Cmd+Enter (Mac), o haz clic en el botón Render. El resultado aparece inmediatamente junto a tu código.
Ejemplo
Aquí hay un gráfico de barras simple con base R — reemplaza los nombres de campo con los tuyos:
barplot(
table(data$species),
main = "Registros por especie",
xlab = "Especie",
ylab = "Conteo",
col = "steelblue"
)Para gráficos más complejos aplica el mismo patrón — escribe o pega cualquier código de R que opere sobre data y produzca un gráfico.
Usar herramientas de IA para ayudar a escribir gráficos
Como los datos son un data.frame estándar de R, puedes usar cualquier herramienta externa de IA para ayudarte a escribir el código del gráfico. Para darle a la IA el contexto que necesita, ejecuta str(data) en el workspace — esto imprime un resumen de la estructura de los datos (nombres de campos, tipos y valores de muestra). Copia esa salida en tu herramienta de IA junto con tu solicitud de gráfico, y la IA podrá escribir código que haga referencia correctamente a tus nombres de campo reales.
Guardar y compartir gráficos
Cuando un gráfico se vea como quieres, guárdalo. Los gráficos guardados se pueden agregar a cualquier panel o reporte desde el editor correspondiente — o enviarse directamente a un panel existente desde la fuente o vista en la que estás trabajando.
Los gráficos se renderizan como SVG, por lo que escalan limpiamente a cualquier tamaño y se ven nítidos al exportarse a PDF.
Filtros y el objeto data
Cualquier filtro activo en la fuente o vista cuando abres la pestaña Plot ya está reflejado en el objeto data — siempre trabajas con el dataset filtrado, no con el completo. Esto te da dos formas de controlar qué entra en un gráfico:
- Filtros hardcodeados en R — escribe la lógica de filtrado directamente en el código del gráfico usando R estándar (por ejemplo
data[data$site == "Sitio-A", ]). Esto hace que el filtro sea permanente y explícito dentro del propio código. - Usar las herramientas de filtro del sistema — aplica filtros a través de la interfaz de filtrado de ISLdata antes de abrir la pestaña Plot. El código se mantiene limpio y general, y el filtro se controla externamente.
Al guardar un gráfico tienes la opción de guardar con los filtros actuales o guardar sin filtros. Guardar sin filtros hardcodeados suele ser la opción más flexible — permite ajustar los filtros activos con las herramientas del sistema y re-renderizar el mismo gráfico al instante para ver cómo cambia. Esto es particularmente útil al iterar sobre subconjuntos: ajustando por año, sitio o especie y actualizando la visualización rápidamente sin tocar el código.
Paquetes de R disponibles
El entorno de gráficos corre en un contenedor Docker preconfigurado con una amplia gama de paquetes comunes de R para manipulación y visualización de datos ya instalados. Si necesitas un paquete que no está disponible, contacta a soporte para agregarlo al entorno. Si te auto-hospedas, tienes control total sobre el contenedor Docker y puedes agregar directamente los paquetes que necesites.
Exportar datos
Puedes exportar datos desde cualquier fuente o vista como un archivo CSV o Excel (XLSX). Funciona igual estés en una fuente o en una vista — la exportación siempre refleja exactamente lo que estás viendo: los campos visibles, en el orden de columnas actual, con cualquier filtro activo aplicado. Lo que ves es lo que obtienes.
Los nombres de campo en la exportación coinciden con lo que ves en pantalla — incluyendo los alias asignados en la configuración de la fuente y los renombrados aplicados en vistas. Esto significa que tu archivo exportado es inmediatamente legible sin necesidad de decodificar IDs internos de campos.
Los resúmenes de Reducir y agrupar (ver Reducir y agrupar) también se pueden exportar desde el panel Analyze de la misma forma.
Organización del espacio de trabajo
A medida que un espacio de trabajo crece, las listas de fuentes, vistas, paneles y reportes pueden volverse largas. ISLdata ofrece a los administradores algunas herramientas ligeras para organizar el espacio de trabajo, de modo que todos puedan encontrar lo que necesitan y el sistema se sienta propio del equipo. Ninguno de estos ajustes cambia cómo se almacenan los datos ni quién puede ver qué — son de presentación y navegación.
Los ajustes de esta página los configura un administrador del espacio de trabajo desde el área de Configuración (icono de engranaje → Configuración). Los miembros regulares verán los resultados — listas categorizadas, el logo del espacio de trabajo, la página de inicio elegida — pero no verán las pantallas de configuración.
Categorías
Las categorías te permiten agrupar fuentes, vistas y reportes en "cubos" nombrados para que las listas se mantengan organizadas a medida que tu espacio de trabajo crece. Cada tipo de objeto tiene su propio conjunto independiente de categorías — la lista de categorías para fuentes es independiente de la de vistas, que a su vez es independiente de la de reportes. Esto te permite organizar cada tipo de objeto del modo que más le convenga (las fuentes pueden agruparse por proyecto o sitio de muestreo; las vistas por audiencia; los reportes por año).
Desde la página de configuración de Categorías, un admin puede:
- Agregar una nueva categoría escribiendo su nombre y presionando Enter (o haciendo clic en el botón de agregar).
- Renombrar una categoría existente editando el nombre en línea.
- Eliminar una categoría — los objetos que tenía asignados quedan sin categoría, pero no se eliminan.
Una vez existen categorías, cualquier fuente, vista o reporte puede asignarse a una desde su página de configuración. Las listas de Fuentes, Vistas y Reportes agrupan entonces las entradas por categoría, con un encabezado por categoría. Los elementos sin categoría aparecen juntos al final de la lista.
Nombres de categoría en varios idiomas
Si tu espacio de trabajo tiene más de un idioma configurado, cada categoría admite un nombre alternativo por idioma. La página de configuración de Categorías muestra una franja de pestañas de idioma; cambia a un idioma no primario para agregar o editar los nombres traducidos. Los usuarios que naveguen las listas verán los encabezados de categoría en su idioma seleccionado.
Si no estás seguro de cómo agrupar las cosas, empieza con un conjunto pequeño — tres a seis categorías por tipo de objeto suele bastar. Siempre puedes agregar más después, y un objeto puede moverse entre categorías en cualquier momento sin afectar sus datos.
Marca y tema
La página de configuración de Marca le permite a un admin darle al espacio de trabajo su propia identidad visual. La marca es por espacio de trabajo, así que una instancia alojada de ISLdata con varios espacios de trabajo puede darle a cada equipo un aspecto distinto sin afectar a los demás.
Logo del espacio de trabajo
Sube una imagen para reemplazar el logo de ISLdata por defecto en la cabecera y en la página de inicio de sesión. El logo subido se almacena de forma privada para tu espacio de trabajo y se muestra dondequiera que aparezca el logo del espacio en la interfaz. Se admiten los formatos de imagen comunes (PNG, JPG, SVG). Para mejores resultados usa un logo que se lea claramente en tamaños pequeños — la cabecera lo muestra alrededor de 32 píxeles de alto — y que tenga fondo transparente o claro para que se vea bien sobre la interfaz de la aplicación.
Si no se ha subido logo, el espacio de trabajo usa el isotipo por defecto de ISLdata.
Tema de color
Elige un tema de color desde el selector de muestras. El tema elegido se aplica a botones, enlaces y otros elementos de acento en todo el espacio de trabajo. Hay varios preajustes disponibles — el predeterminado más variantes azul, verde, púrpura y turquesa — de modo que un espacio de trabajo pueda adoptar un color que coincida con la identidad del equipo o lo distinga de otros espacios a los que el usuario pertenece.
Los cambios de tema y logo surten efecto inmediatamente para todos los usuarios del espacio de trabajo; no necesitan cerrar sesión ni refrescar nada más que la página en la que están.
Página de inicio del espacio de trabajo
Por defecto, al abrir el espacio de trabajo aterrizas en la lista de Fuentes. Desde la página de configuración Página de inicio, un admin puede cambiar ese destino de aterrizaje a cualquier panel del espacio de trabajo.
Cuando se configura un panel como página de inicio, cada usuario que navegue a la raíz del espacio de trabajo verá primero ese panel. La barra lateral sigue dando acceso completo a Fuentes, Vistas, Paneles y Reportes, así que es un cambio de presentación, no de permisos. Usos comunes incluyen:
- Un tablero de estado que muestra el avance de la recolección de datos en los proyectos activos.
- Un mapa o gráfico resumen que orienta al equipo al inicio del turno.
- Un panel pinneado tipo reporte para grupos de interés que solo inician sesión ocasionalmente y quieren una vista de "qué hay de nuevo".
Para quitar la página de inicio y volver a la lista de Fuentes por defecto, el admin limpia la selección en la página de configuración de Página de inicio.
El panel de página de inicio se muestra a todos los usuarios que tienen acceso a él. Los usuarios que no tienen permiso sobre el panel elegido verán la lista de Fuentes en su lugar — establece los permisos del panel en consecuencia.
Permisos y compartir
El control de acceso en ISLdata aplica a cada objeto del sistema — fuentes, vistas, paneles y reportes tienen cada uno su propia configuración de permisos independiente. Esto significa que puedes dar a un usuario acceso a una vista curada de los datos sin darle acceso a la fuente subyacente, o compartir un panel públicamente manteniendo privada la fuente de la que se nutre.
Cómo funcionan los permisos
Los permisos se establecen por usuario y por objeto. Hay dos niveles:
- Lectura — el usuario puede ver el objeto y sus datos, pero no puede hacer cambios.
- Escritura — el usuario puede leer y editar datos dentro del objeto (agregar, modificar o eliminar registros donde aplique).
Los administradores del espacio de trabajo saltan todas las comprobaciones de permisos — por defecto tienen acceso completo a todo dentro del espacio. Para el resto de usuarios, solo aparecen en su navegación los objetos a los que se les ha otorgado acceso explícitamente.
| Objeto | Lectura otorga | Escritura otorga |
|---|---|---|
| Fuente | Navegar registros, filtrar, exportar | Además: agregar, editar, importar y archivar registros |
| Vista | Navegar y exportar datos de la vista | Además: editar registros a través de la vista (los cambios se guardan en la fuente) |
| Panel | Ver el panel | Además: editar el diseño y la configuración de los widgets |
| Reporte | Ver y leer el reporte | Además: editar el contenido y la estructura del reporte |
Un patrón común es dar a la mayoría del equipo acceso de lectura a las fuentes (protegiendo los datos crudos) y acceso de escritura solo a vistas específicas. De este modo, las ediciones fluyen a través de una interfaz curada mientras la fuente queda protegida de cambios accidentales.
Si necesitas acceso a un objeto que no puedes ver, contacta a tu administrador del espacio de trabajo. Solo los administradores pueden otorgar y revocar permisos.
Iniciar sesión
ISLdata usa autenticación sin contraseña. No hay contraseña que crear, recordar ni restablecer. Así funciona:
- Ve a tu instancia de ISLdata e ingresa tu dirección de correo electrónico.
- Revisa tu bandeja de entrada — recibirás un correo con un enlace seguro de inicio de sesión.
- Haz clic en el enlace. Ya estás dentro y tu sesión queda establecida.
El enlace de inicio de sesión es de un solo uso y tiene tiempo limitado por seguridad. Si expira, simplemente solicita uno nuevo. Necesitas acceso a una cuenta de correo segura — ese es tu factor de autenticación en lugar de una contraseña.
Si no recibes el correo de inicio de sesión, revisa la carpeta de spam o correo no deseado. El correo proviene del remitente SMTP configurado por tu organización. Si aún así no puedes iniciar sesión, contacta a tu administrador del espacio de trabajo.
Cambiar de espacio de trabajo
Si eres miembro de más de un espacio de trabajo, puedes moverte entre ellos sin volver a pasar por el flujo de inicio de sesión por correo cada vez.
- Haz clic en tu nombre en la esquina superior derecha de la cabecera para abrir el menú de usuario.
- Bajo el encabezado Espacios de trabajo verás cada espacio al que perteneces. El espacio en el que estás actualmente aparece marcado o resaltado.
- Haz clic en cualquier otro espacio de la lista — ISLdata te conecta a él y te lleva directamente allí.
La sección Espacios de trabajo solo aparece cuando perteneces a más de uno. Si esperas ver alguno y no aparece, pídele al administrador de ese espacio que agregue tu correo a su lista de usuarios.
Preferencias
Tus preferencias de usuario incluyen la selección de tema (claro, oscuro o automático) y los ajustes de visualización por defecto. Se almacenan por usuario y no afectan a otros usuarios del espacio de trabajo.
Para organizar el espacio de trabajo en sí — categorizar fuentes, vistas y reportes, configurar el logo o tema del espacio, o elegir un panel como página de inicio — ver Organización del espacio de trabajo.
Entender tus permisos
Tu acceso a fuentes, vistas, paneles y reportes específicos está controlado por los permisos que un administrador del espacio de trabajo te haya asignado. Solo verás en la barra lateral los elementos a los que tienes acceso.
Si necesitas acceso a una fuente o vista que no puedes ver, contacta a tu administrador del espacio de trabajo. Puede otorgarte acceso de lectura (para ver los datos) o de escritura (para editar registros) por cada recurso.
| Rol | Lo que puedes hacer |
|---|---|
| Miembro del espacio de trabajo | Acceder a fuentes, vistas, paneles y reportes a los que se te haya dado permiso. Exportar datos. Editar registros en fuentes/vistas donde tengas acceso de escritura. |
| Administrador del espacio | Todo lo que puede hacer un miembro, además de: gestionar usuarios, establecer permisos, ver el registro de auditoría completo, crear y configurar todos los recursos. |